I've spent the last few weekends playing with Haskell OpenGL programming. It's pretty awesome. I've begun to see the design of larger haskell programs as a thin imperative shell around a pure functional core. At first, I followed along with everyone else, doing everything in the IO monad, but there is a better way. Two key insights led me to this shell style program.
First, i realized game state really had to live in an IO ref. That made me sad, so i took up a policy of containment. The OpenGL windowing system works on callbacks. you have to specify the functions that will actually handle keystrokes, but they don't have to do any work. I guess an example is in order:
> {-# OPTIONS -fglasgow-exts #-}
> import Data.IORef
> import qualified Graphics.UI.GLUT as GL
> import System.Exit
Three things to take care of. 1. Initialize OpenGL. 2. Create the game world. 3. Set up the callbacks. The window Utilities actually enter into a main loop that keeps track of all the openGL gunk. when it's time to render a new frame, the Display callback is responsible for sending commands to the GL device. The idle callback tells us how to update the world as time passes. The keyboardMouseCallback is, shockingly, called when the user clicks the mouse, moves the mouse, or types.
> main = do
> (progname, _) <- GL.getArgsAndInitialize
> window <- initGL
> gameEnv <- newIORef initialWorld
> GL.displayCallback $= (display gameEnv)
> GL.idleCallback $= Just (idle gameEnv)
> GL.keyboardMouseCallback $= Just (keyboardMouse window gameEnv)
> GL.mainLoop
The initGL method is at the end, because it's boring. It's just what you'd expect to see in any random openGL tutorial. The callbacks are here, because they're slightly more interesting. Notice how they pass *all* the work off to helper methods.
Display gets the current game state, and asks render to render it.
> display gameEnv = do
> GL.clear [GL.ColorBuffer , GL.DepthBuffer]
> env <- GL.get gameEnv
> render $ world env
> GL.swapBuffers
The idle method keeps track of how much time is passing. time and game state gets passed on to tick.
> idle gameEnv = do
> env <- GL.get gameEnv
> time <- GL.get GL.elapsedTime
> gameEnv $= tick time env
> GL.postRedisplay Nothing
Finally input handling. Virtually the same as idle, grab the state change, and pass it on to the pure handler.
> keyboardMouse window _ (GL.Char '\ESC') GL.Down _ _ = do
> GL.destroyWindow window
> exitWith ExitSuccess
> keyboardMouse _ gameEnv key state modifiers position = do
> env <- GL.get gameEnv
> gameEnv $= userAction env key state
Now we've got our callbacks... what do they actually do?
Time for some datatypes
> type Time = Int
> data GameEnv = GameEnv Time User
> deriving Show
> data User = User { playerX :: GL.GLfloat,
> playerY :: GL.GLfloat,
> playerVelocityX :: GL.GLfloat,
> playerVelocityY :: GL.GLfloat,
> playerRotation :: GL.GLfloat,
> playerVelocityRotation :: GL.GLfloat
> }
> deriving Show
>
> initialWorld = GameEnv 0 $ User 0 0 0 0 0 0
Our game environment is simply a clock, and some bookkeeping state about the user's position and velocity. Obviously, store whatever you need to here. If bad guys should chase the user, this is where you store their state. This example renders the world based on time, to keep things simple.
The idle timer calls tick once for each pass through the mainloop. This reflects time passing in the world. If you have bad guys, move them here. Two things are going on, and perhaps it's a little confusing. First the elapsed time is calculated, and stored in the new game environment. Second, the player's position is updated based on their current velocity in the x, and y dimensions. The rotation is updated based on the angular velocity.
> tick :: Int -> GameEnv -> GameEnv
> tick tnew (GameEnv 0 usr) = GameEnv tnew usr
> tick tnew (GameEnv told usr) = GameEnv tnew u
> where u = usr{playerX = (playerVelocityX usr)/100 * elapsed + (playerX usr),
> playerY = (playerVelocityY usr)/100 * elapsed + (playerY usr),
> playerRotation = (playerVelocityRotation usr)/100 * elapsed + (playerRotation usr)}
> elapsed = fromIntegral $ tnew - told
Next, player actions. I think these are ugly because of their verbosity. and there's lots of them. However, they are very simple. I simply set the velocity. a nicer approach would set acceleration, and cap the maximum velocity. That lets you ease in and ease out of motion, but that code gets fairly opaque.
Arrow up, moves the player forward, arrow down moves back.
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyUp) GL.Down = GameEnv t u
> where u = usr{playerVelocityX = sin $ pi / 180 * playerRotation usr,
> playerVelocityY = 0 - (cos $ pi / 180 * playerRotation usr)}
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyUp) GL.Up = GameEnv t u
> where u = usr{playerVelocityX = 0, playerVelocityY = 0}
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyDown) GL.Down = GameEnv t u
> where u = usr{playerVelocityX = 0 - (sin $ pi / 180 * playerRotation usr),
> playerVelocityY = cos $ pi / 180 * playerRotation usr}
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyDown) GL.Up = GameEnv t u
> where u = usr{playerVelocityX = 0, playerVelocityY = 0}
Left and right, update the player rotation velocity.
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyLeft) GL.Down = GameEnv t u
> where u = usr{playerVelocityRotation = (-10)}
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyLeft) GL.Up = GameEnv t u
> where u = usr{playerVelocityRotation = 0}
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyRight) GL.Down = GameEnv t u
> where u = usr{playerVelocityRotation = 10}
> userAction (GameEnv t usr) (GL.SpecialKey GL.KeyRight) GL.Up = GameEnv t u
> where u = usr{playerVelocityRotation = 0}
I considered the standard W A S D keys, but I wanted to figure out the special keys. I use Q W for strafe, so there is an example of side to side motion.
> userAction (GameEnv t usr) (GL.Char 'q') GL.Down = GameEnv t u
> where u = usr{playerVelocityY = 0- (sin $ pi / 180 * playerRotation usr),
> playerVelocityX = 0- (cos $ pi / 180 * playerRotation usr)}
> userAction (GameEnv t usr) (GL.Char 'q') GL.Up = GameEnv t u
> where u = usr{playerVelocityX = 0, playerVelocityY = 0}
> userAction (GameEnv t usr) (GL.Char 'w') GL.Down = GameEnv t u
> where u = usr{playerVelocityY = (sin $ pi / 180 * playerRotation usr),
> playerVelocityX = (cos $ pi / 180 * playerRotation usr)}
> userAction (GameEnv t usr) (GL.Char 'w') GL.Up = GameEnv t u
> where u = usr{playerVelocityX = 0, playerVelocityY = 0}
Anything else, ignore.
> userAction g _ _ = g
That pretty much covers my first insight, forcing state as high up as possible. Main, is in the IO monad. The callbacks are in the IO monad. Everything else is pure. Everything else is QuickCheck-able. The trick to rendering, I feel, is preserving purity. My solution is a dsl. Constructing the world is constructing a list of OpenGL commands for the renderer to execute.
Existential types seem to be the only way out. Existential types allow us to group things simply by functionality. So, many datatypes instance the same class. First and foremost, GLCommand. a glcommand has a render method, it executes in the IO monad. So, the intention is, we will render a list of renderable things.
> class GLCommand a where
> render :: a -> IO ()
Next, the Existential type. This says anything that is a GLCommand, is also a GLC. a GLC is renderable. We get to make lists of GLC's, the only requirement is that each element is renderable, each element has a render method.
> data GLC = forall a. GLCommand a => GLC a
> instance GLCommand GLC where
> render (GLC a) = render a
The wiki has a much more coherent explanation of existential types, check it out here: http://www.haskell.org/haskellwiki/Existential_type
There's a few fundamental operations I'd like to use to compose my scene. Matrix operations, vertex creation, colors. My approach creates a datatype that encapsulates everything the render method will need to generate the GL operation at render time. I have 4 basic matrix operations. All I do is wrap up the desired state in a datatype.
> rotate :: GL.GLfloat -> GL.GLfloat -> GL.GLfloat -> GL.GLfloat -> GLC
> rotate a v1 v2 v3 = GLC $ ActionRotate a (GL.Vector3 v1 v2 v3)
> scale :: GL.GLfloat -> GL.GLfloat -> GL.GLfloat -> GLC
> scale x y z = GLC $ ActionScale x y z
> translate :: GL.GLfloat -> GL.GLfloat -> GL.GLfloat -> GLC
> translate x y z = GLC $ ActionTranslate (GL.Vector3 x y z)
> identity = GLC $ (ActionIdentity :: MatrixActions GL.GLfloat)
The actual datatype is simple. Again, just hold the data that the GL methods will require at render time.
> data GL.MatrixComponent a => MatrixActions a = ActionRotate a (GL.Vector3 a)
> | ActionScale a a a
> | ActionTranslate (GL.Vector3 a)
> | ActionIdentity
Finally instancing the GLCommand class, The render method does the work of rotation, or scaling, or whatever is necessary. This style fully separates the IO stuff from rendering a scene.
> instance GL.MatrixComponent a => GLCommand (MatrixActions a) where
> render = matrixActions
> matrixActions (ActionRotate angle vec) = GL.rotate angle vec
> matrixActions (ActionScale x y z) = GL.scale x y z
> matrixActions (ActionTranslate vec) = GL.translate vec
> matrixActions (ActionIdentity) = GL.loadIdentity
Vertex creation, and setting colors follow a similar pattern.
> data GL.VertexComponent a => VertexActions a = ActionVertex (GL.Vertex3 a)
> instance GL.VertexComponent a => GLCommand (VertexActions a) where
> render = vertexActions
> vertexActions (ActionVertex vec) = GL.vertex vec
> vertex :: GL.GLfloat -> GL.GLfloat -> GL.GLfloat -> GLC
> vertex x y z = GLC $ ActionVertex (GL.Vertex3 x y z)
> data GL.ColorComponent a => ColorActions a = ActionColor (GL.Color3 a)
> instance GL.ColorComponent a => GLCommand (ColorActions a) where
> render = colorActions
> colorActions (ActionColor c) = GL.color c
> color :: GL.GLfloat -> GL.GLfloat -> GL.GLfloat -> GLC
> color r g b = GLC $ ActionColor (GL.Color3 r g b)
The final operations were inspired by http://www.cs.unm.edu/~williams/cs257/graphics.html The idea is when rendering sometimes we want to draw things one after the other, in series. However, sometimes we want to draw a little bit, then go back, and draw a bit more. An example might be drawing the branches of the tree. After drawing the trunk, draw one branch away from the trunk, then jump back to the trunk and draw another branch.
So here are the basic operations:
> triangles commands = GLC $ RenderTriangles commands
> serial commands = GLC $ RenderSerial commands
> parallel commands = GLC $ RenderParallel commands
Now, rather than simple operations I gather lists of operations.
> data RenderActions = RenderTriangles [GLC]
> | RenderSerial [GLC]
> | RenderParallel [GLC]
> instance GLCommand RenderActions where
> render = renderActions
> renderActions (RenderTriangles commands) = GL.renderPrimitive GL.Triangles $ mapM_ render commands
> renderActions (RenderSerial commands) = mapM_ render commands
> renderActions (RenderParallel commands) = mapM_ (GL.preservingMatrix . render) commands
The world itself. World's job is to take the current game environment, then come up with a list of commands to execute to render that world.
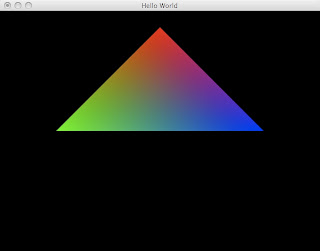
> world (GameEnv t u) = serial [ identity,
> rotate (playerRotation u) 0 1 0,
> translate (0 - playerX u) 0 (0 - playerY u),
> translate 0 0 (-4),
> rotate trotation 0 1 0,
> triangles [ color 1 0 0,
> vertex 0 1 0,
> color 0 1 0,
> vertex (-1) 0 0,
> color 0 0 1,
> vertex 1 0 0]]
> where trotation = (fromIntegral t) / 10
This is some random housekeeping stuff, initialization of GL and a few commands to clean up the syntax a bit.
> ($=) :: (GL.HasSetter s) => s a -> a -> IO ()
> ($=) = (GL.$=)
> initGL = do
> GL.initialDisplayMode $= [GL.DoubleBuffered]
> GL.initialWindowSize $= GL.Size 640 480
> GL.initialWindowPosition $= GL.Position 0 0
> window <- GL.createWindow "Hello World"
> GL.clearColor $= GL.Color4 0 0 0 0
> GL.viewport $= (GL.Position 0 0 , GL.Size 640 480)
> GL.matrixMode $= GL.Projection
> GL.loadIdentity
> GL.perspective 45 ((fromIntegral 640)/(fromIntegral 480)) 0.1 100
> GL.matrixMode $= GL.Modelview 0
> return window
It would be great to expand the existential types to only allow the setting of vertexes in a triangle command. I haven't gotten around to that in my toy programs.
There you go. A complete system for developing large opengl applications in a few hundred lines of code.


